4.1 머신러닝 이란?
머신러닝이란? 수많은 데이터를 학습시켜 거기에 있는 패턴을 찾아내는 것
# 어떻게 특징과 규칙을 찾으면 좋을까?
머신러닝에서는 벡터라는 것이 굉장히 중요합니다.
벡터란 공간에서 크기와 방향을 가진 것을 의미합니다.
어떤 요소가 모여있는 것을 "특징량"이라고 하고
특징량을 기반으로 구분선을 그으면 판단하기가 쉽습니다.
이처럼 구분선을 찾아내는 것이 머신러닝입니다.
점과 점 사이를 구해서 가까우면 비슷한 데이터를 인식한다.
#특징추출
머신러닝을 하려면 데이터가 어떤 특징을 가지고 있는지 찾고 벡터로 만들어야 합니다. 이 같은 변환 처리를 '특징 추출'이라고 합니다.
머신러닝 프레임워크는 범용적인 것입니다. 어떤 특징을 추출할지는 프로그래머가 결정해야 합니다. 이것이 바로 머신러닝의 포인트입니다. 머신러닝에서 학습을 기반으로 분류 등을 하는 시스템을 '학습 기계'라고 부르는데, '분류/식별기', '학습기'라고 부르기도 합니다.
#회귀분석이란?
회귀분석이란 통계 용어인데, Y가 연속된 값일때 Y=f(x)와 같은 모델로 나타내는 것입니다. 회귀에서 사용하는 가장 기본적인 모델은 Y=aX+b입니다. 이를 '선형 회귀'라고 부릅니다. 이러한 모델에서 Y는 연속 측정의 종속변수(목표변수), X를 독립변수(설명 변수)라고 부릅니다.
#머신러닝의 종류
1. 교사학습 : 데이터와 함께 답을 입력합니다. 다른 데이터의 답을 예측합니다.
2. 비교사 학습: 데이터는 입력하지만 답은 입력하지 않습니다. 다른 데이터의 규칙성을 찾습니다.
3. 강화학습 : 부분적으로 답을 입력합니다. 데이터를 기반으로 최적의 답을 찾아냅니다.
#머신러닝의 흐름
1. 데이터의 수집
2. 데이터의 가공 - 프로그램이 다루기 쉬운 형태
3. 데이터 학습
1) 학습 방법 선택 - SVM, 랜덤포레스트, K-MEANS
2) 매개변수 조정
3) 모델학습
4. 모델평가
#머신러닝 응용분야
1. 클래스 분류 - 스팸메일분류, 필기인식,증권사기
2. 클러스터링(그룹나누기) - 사용자의 취향을 그룹으로 나누어 사용자 취향에 맞는 광고를 제공
3. 추천 - 사용자가 인터넷 서점에서 구매한 책들을 기반으로 다른 책을 추천
4. 차원축소 - 데이터를 시각화하거나 구조를 추출해서 용량을 줄여 계산을 빠르게 하거나 메모리를 절약할때 사용
6.초과학습-훈련전용 데이터가 학습돼 있지만 학습되지 않은 새로운 데이터에 대해 제대로 된 예측을 못하는 상태
4-2. 머신러닝 첫걸음
머신러닝 프레임워크 scikit-learn(사이킷런)
분류, 회귀, 클러스터링, 차원축소
장점
사이킷런 파이썬 프레임워크는 탄탄한 학습 알고리즘이 장점
잘 정의된 알고리즘과 통합 그래픽, 검증된 라이브러리라는 것도 장점
설치, 학습, 사용하기 쉽고 예제와 사용 설명서가 잘 돼 있음
단점
딥러닝이나 강화 학습을 다루지 않는 단점
그래픽 모델과 시퀀스 예측(Sequence Prediction) 기능을 지원하지 않음
파이썬 이외의 언어에서는 사용할 수 없고, 파이썬 JIT(Just-in-Time) 컴파일러인 파이파이(PyPy)나 GPU를 지원하지 않음
사이킷런 분류 정리 ( https://scikit-learn.org/stable/auto_examples/classification/plot_classifier_comparison.html )
#텐서플로우
텐서플로우는 구글이 내놓은 이식성 좋은 머신러닝과 인공 신경망 라이브러리
배우기가 조금 어렵지만 성능과 확장성이 좋음
텐서플로우에는 딥러닝에서 많이 사용하는 다양한 모델과 알고리즘이 들어 있으며 GPU(훈련용)나 구글 TPU(현업에 적용할 수 있는 규모로 예측용)를 장착한 하드웨어에서 탁월한 성능
4.2.1. scikit-learn 설치
pip install -U scikit-learn scipy matplotlib scikit-image
4.2.2. 데이터를 읽어 들이고 분할할 때 편리한 Pandas 설치
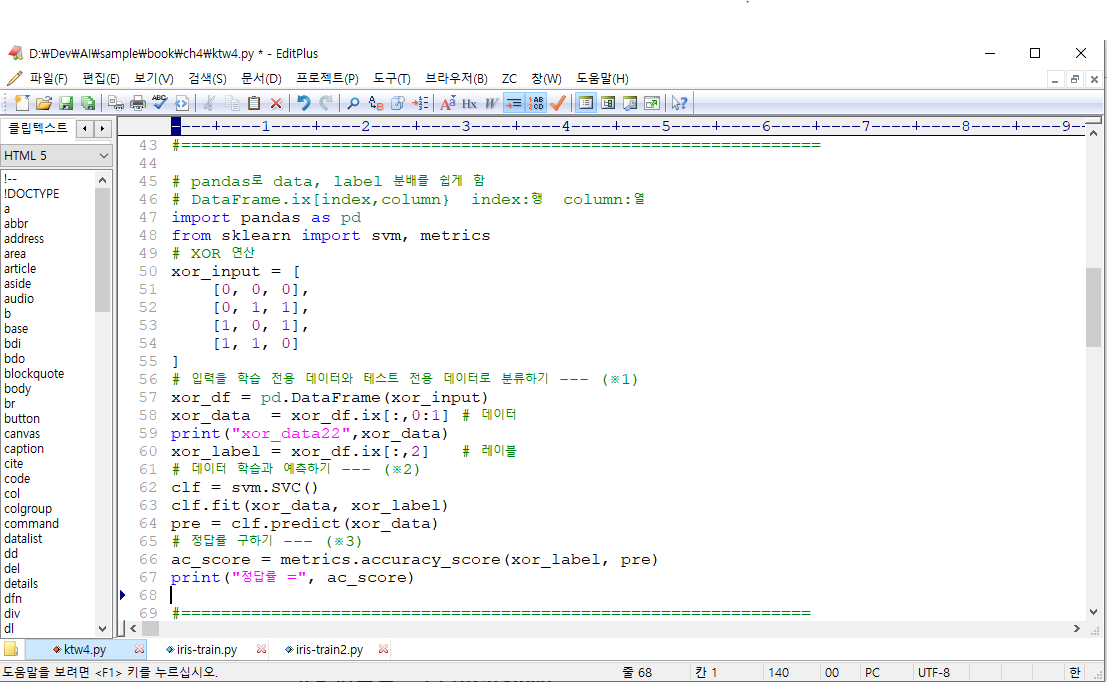
XOR 연산 학습해보기
pip install pandas
[학습요점]
1. clf = svm.SVC() #알고리즘 선택
2. clf.fit( 훈련데이터, 훈련라벨 ) #학습하기
3. result = clf.predict( 테스트데이터 ) #예측하기
4. as_score = metrics.accuracy_score(테스트라벨, 예측결과 ) #정답률 구하기
붓꽃의 품종 분류하기
[학습요점]
1. 데이터
5.1 3.5 1.4 0.2 Iris-setosa
4.9 3 1.4 0.2 Iris-setosa
2. 데이터 분류하기
train_data, test_data, train_label, test_label = train_test_split(csv_data, csv_label)

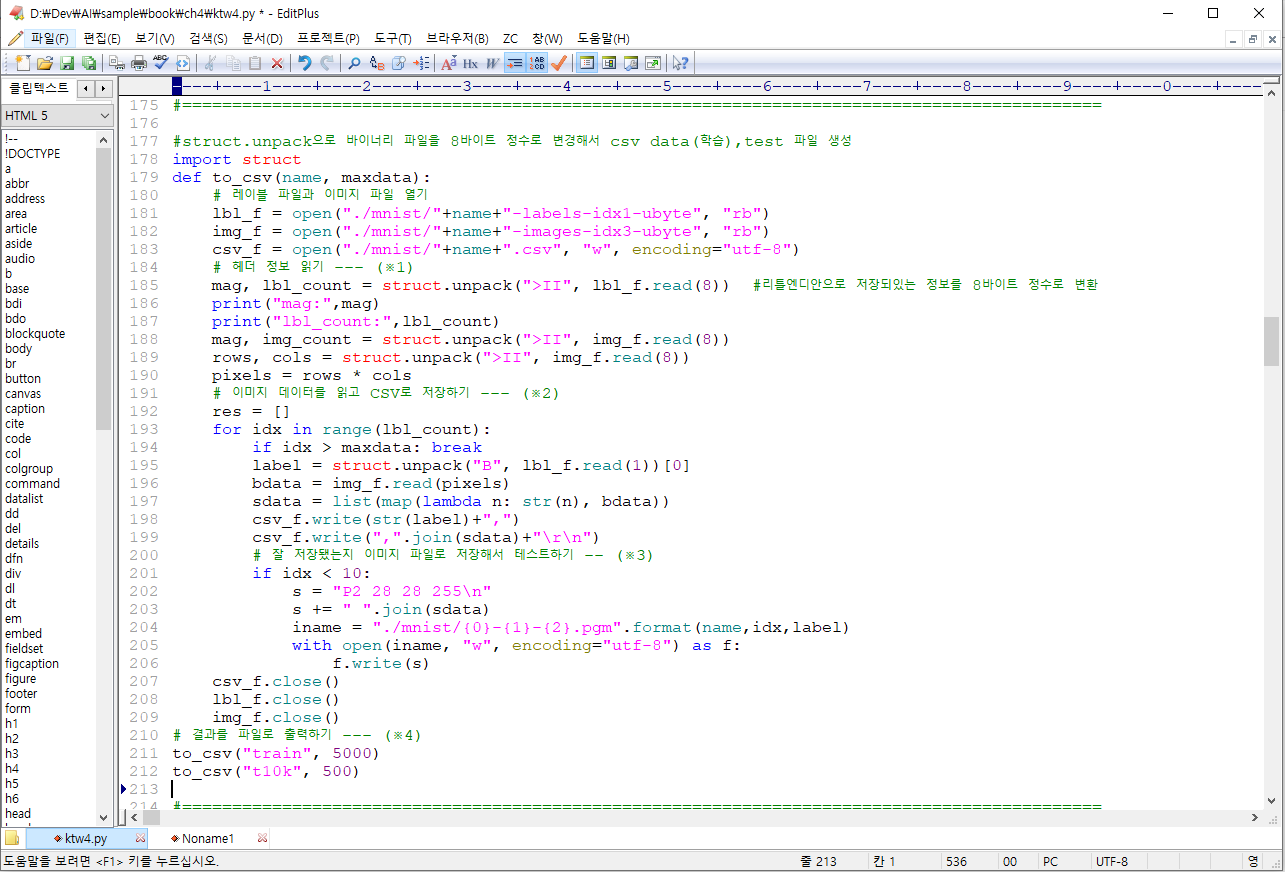
4.3 이미지 내부의 문자 인식
손글씨 숫자 인식하기
[학습요점]
1. 데이터 가공
바이너리 파일을 8바이트 정수로 변경
mag, lbl_count = struct.unpack(">II", lbl_f.read(8)) #리틀엔디안으로 저장되있는 정보를 8바이트 정수로 변환
7 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 84 185 159 151 60 36 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 222 254 254 254 254 241 198 198 198 198 198 198 198 198 170 52 0 0 0 0 0 0 0 0 0 0 0 0 67 114 72 114 163 227 254 225 254 254 254 250 229 254 254 140 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 17 66 14 67 67 67 59 21 236 254 106 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 83 253 209 18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 22 233 255 83 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 129 254 238 44 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 59 249 254 62 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 133 254 187 5 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 9 205 248 58 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 126 254 182 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 75 251 240 57 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 19 221 254 166 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 3 203 254 219 35 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 38 254 254 77 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 31 224 254 115 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 133 254 254 52 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 61 242 254 254 52 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 121 254 254 219 40 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 121 254 207 18 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
3. 훈련 데이터가 많아지면 정확도가 높아진다.
책의 내용에서는 5000개 학습과 60000개 학습시 정확도의 차이를 보여준다 79% ---> 95%

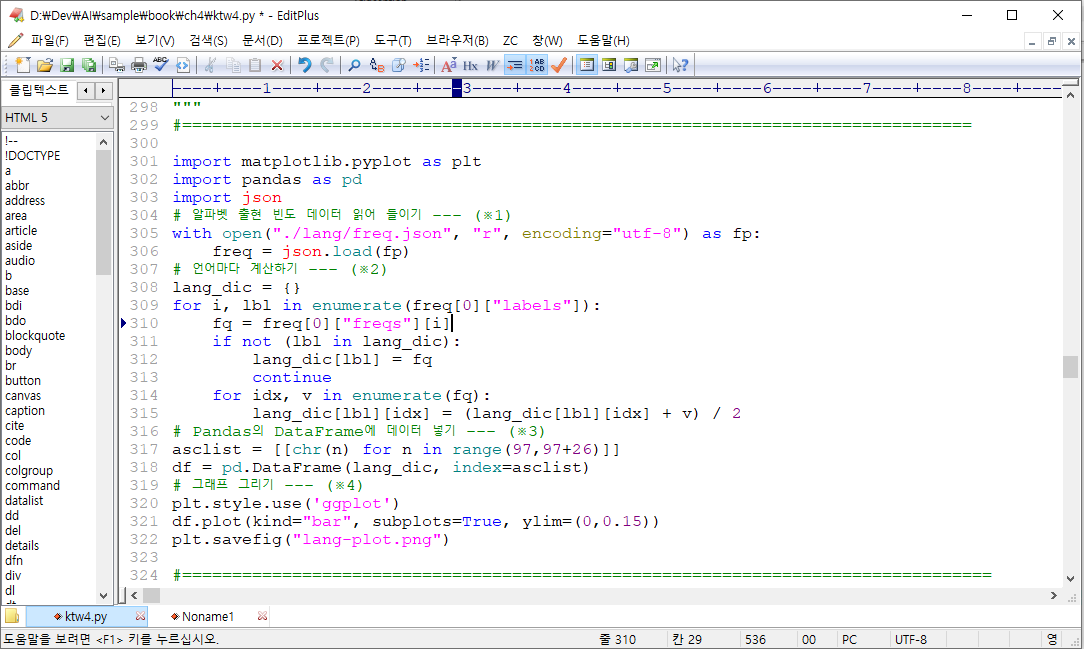
4.4 외국어 문장 판별하기
알파벳의 출현빈도로 언어 판별
[학습정리]
1. 데이터 가공
원본파일
Vous lisez un « bon article ».
Palais de Westminster, l'abbaye de Westminster et l'église Sainte-Marguerite *
가공파일 (알파벳 사용 백분율)
[0.07595212187159957, 0.012840043525571273, 0.04570184983677911, 0.04613710554951034, 0.10533188248095757, 0.015669205658324265, 0.019151251360174103, 0.043743199129488576, 0.07399347116430903, 0.0017410228509249185, 0.00544069640914037, 0.05375408052230685, 0.026332970620239392, 0.07747551686615888, 0.08966267682263329, 0.016539717083786723, 0.0, 0.07769314472252448, 0.061371055495103376, 0.08052230685527748, 0.02589771490750816, 0.009793253536452665, 0.014145810663764961, 0.0006528835690968443, 0.02002176278563656, 0.0004352557127312296]

2. 그래프

파이썬 내 서버 설정하기 실패
docker commit c132b8ceff5a mlearn:init
docker run -i -t -v /d/Dev/AI/sample:/sample mlearn:init -p 8080:8080 mlearn
4.5 서포트 벡터 머신(SVM)
SVM은 선을 구성하는 매개변수를 조정해서 요소들을 구분하는 선을 찾고, 이를 기반으로 패턴을 인식하는 방법입니다. 중간을 지나가는 선 찾기. 마진최대화
scikit-learn을 이용하면 학습 알고리즘을 쉽게 변경할 수 있습니다.
SVM에는 SVC/LinearSVC 등의 다양한 알고리즘이 있고 각각의 특징이 다릅니다
[학습요점]
1. 알고리즘 변경
clf = svm.SVC()
clf = svm.LinearSVC()
2. 데이터 가공
187/200 62/100 thin
195/200 65/100 thin

4.6. 랜덤 포레스트
학습전용 데이터를 샘플링해서 여러 개의 의사결정 트리를 만들고, 만들어진 의사결정 트리를 기반으로 다수결로 결과를 결정하는 방법입니다.
버섯분류
[학습요점]
1. 데이터 가공
원본데이터
e x s y t a f c b k e c s s w w p w o p n n g
가공데이터
[0,0,0,0,1,0,0,0,0,0,0,0]
연속변수가 아닌 경우 분류변수로 사용
2. 랜덤 포레스트 알고리즘 사용
clf = RandomForestClassifier()

4.7. 데이터를 검증하는 방법
크로스 밸리데이션(교차검증)
[학습요점]
1. 크로스 밸리데이션
1) 분류를 A,B,C로 나누고
2) AB-C, AC-B, BC-A
3) 3분류의 평균을 구해 최종적인 분류 정밀도를 구합니다
'인공지능' 카테고리의 다른 글
| 5. 딥러닝 (0) | 2019.12.01 |
|---|---|
| 2장. 고급스크레이핑 (0) | 2019.11.24 |
| 1장. 크롤링과 스크레이핑 (0) | 2019.11.24 |
| 파이썬 문법 간단정리 (1) | 2019.11.24 |
| 머신러닝/딥러닝 개발을 위한 환경설정 (1) | 2019.11.24 |


